
目次
Contents
【GPTsにBacklogのコメントを翻訳させたい】
こんにちは、熊本事業所のY・Mです。
ChatGPT初心者の筆者が、社内で利用している既存ツールと連携させて何かをアウトプットする処理を開発するシリーズ2回目の記事です。
【前回記事はこちら】
前回の記事にて、何を開発するか簡単ながら検討を実施し、「Backlogについた外国語のコメントを翻訳させる」処理の開発に取り組もうと考えたところまで書かせていただきました。今回の記事では、実際に開発を行っていきます。
他の方の事業部ブログとは少々趣が異なる記事ですが、どなたかの参考になれば幸いです。
※なお、本記事で扱う事柄は筆者が個人的な興味・関心で取り組んだ内容の共有です。弊社がビジネスとして行っているものではございません。諸々至らない点はご容赦ください。
※記載している内容は、2024年5月時点のものです。
【前回からの実現イメージの見直し】
実現するもののイメージを改めて具体化する過程において、前回の記事を書いたときと認識が変わった点がありました。
1.ChatGPT APIを叩くソリューションは、GPTs爆誕後はどうやらコスパ悪い
初心者である筆者は、前回の記事を書いた時点では「”ChatGPT API”を使用すればその他サービスとのAPI連携は想像しやすいよね~」と漠然と考えていました。しかしChatGPT APIは従量課金制です。日本語だと1トークンが約1文字、漢字だと数トークンに相当することもあるとのことです。あっという間に数千数万トークン消費することが容易に想像できます。また、生成モデルによっても料金が異なります。
その点、2023年11月に発表された「GPTs」は有料プランの月額のみで使い放題で「Custom Actions」機能にて外部サイトAPIを呼び出す処理も可能です。最新生成モデルも追加料金無しで使用できます。
これは断然GPTsのほうが「Chat GPTの使用量」に対してのコストパフォーマンスが良いと考えられるでしょう。
※ただし、ChatGPT APIは無料プランでも利用できますがGPTsは有料プランでしか利用できません(2024年5月現在)。
2.ChatGPT APIを使わずGPTsを使用すると考えた場合、「自動で何かさせる」処理が組みにくい
ChatGPT APIはコスパが悪いことに気づいてGPTsに切り替えてみることにしたものの、いざ自分のGPTsを作成しようとしてみると、それまでイメージしていた処理の流れからは考え方を変える必要があることがわかってきました。
当初漠然とイメージしていた流れ
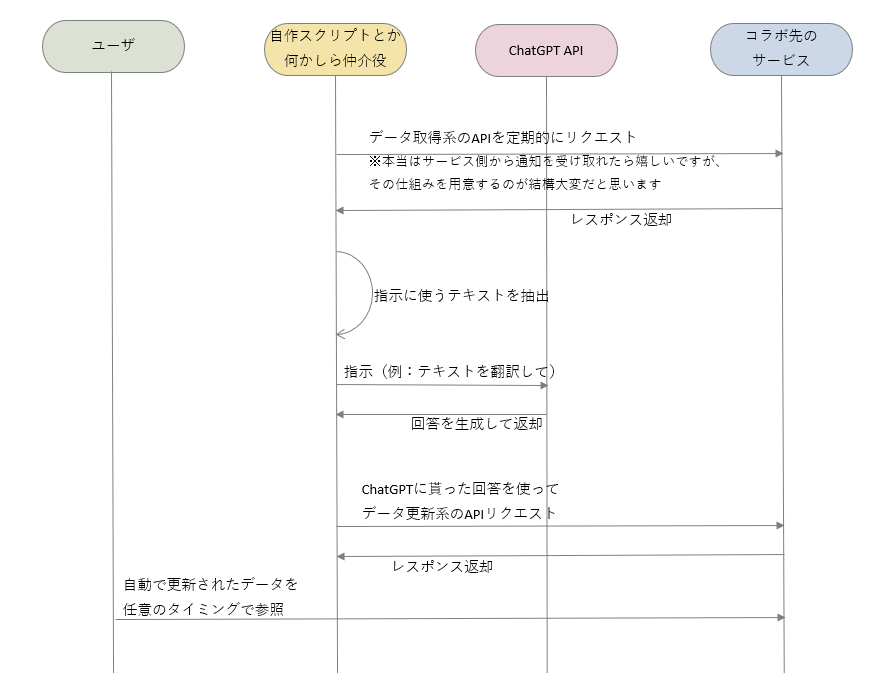
正直、こちらのほうが慣れていてイメージしやすいのです。
しかし…
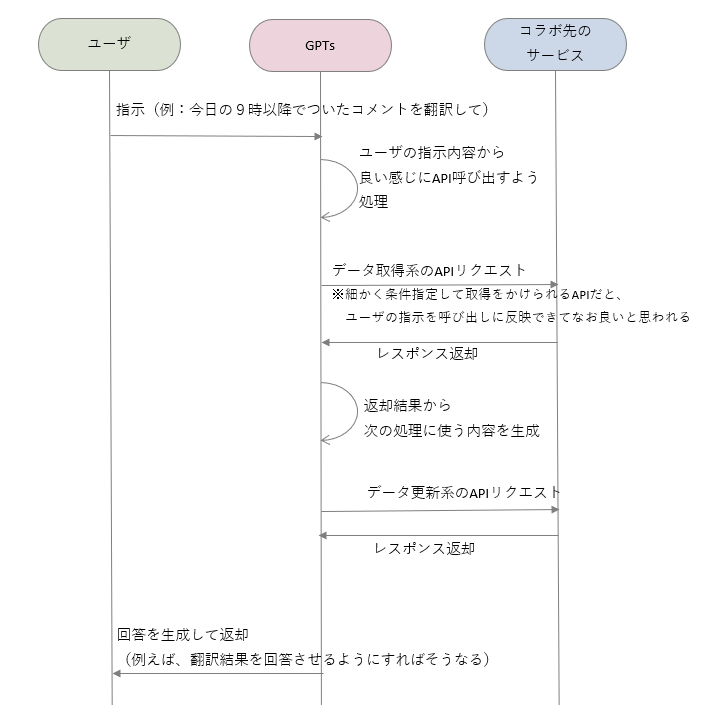
GPTsが得意な流れって、もしかしてこうなのでは…?
あくまでユーザの問いかけが起点でGPTsからの回答が終点となり、上の図とはかなり流れが異なりますよね。
2024年5月時点での現状として、「ChatGPTとユーザの対話を中心に置いたプロダクト」なら有料プランのサブスクの範囲内で実現できるようにしている一方で、「外部サービスを中心に置いたプロダクト」はそうではなく従量課金制とするというのがOpen AI社の方針であるととれます。
当初イメージしていたのは「Backlogについた外国語コメントを自動でChatGPTに翻訳させ、Backlogに返信する。ユーザは好きなときに翻訳結果を見られる」ようなものでしたが、GPTsとユーザの対話を中心として再構成し、「GPTsに話しかけて、Backlogスペースの最近の更新の中から外国語のコメントを探させ、翻訳させる」ような流れとすることにしました。
以上を踏まえて、こんな流れの実現イメージとなりました。
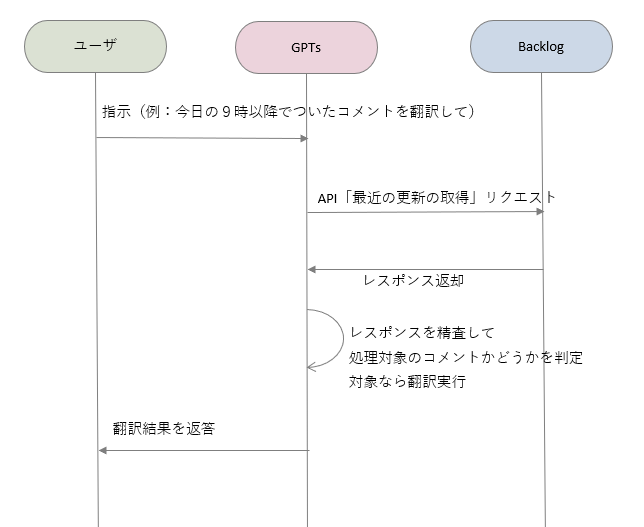
上記を実現した開発手順を、以下でご説明します。
【注意事項】
作成したGPTsを一般に公開する前提では作成しておりません。
自分ならびに社内の関係者で利用する程度の範囲を想定して作成しておりますので、参考にしていただく場合は、利用範囲を明確にした上で必要なセキュリティ上の措置やルールの策定を講じていただく必要があります。
また、GPTsに取得させるBacklogのデータには情報セキュリティ上の問題を生じさせる内容を含まないことを事前にご確認ください。
【準備】
・BacklogにてAPIキーを発行しておく
参考: APIの設定 – Backlog ヘルプセンター
※Backlogを運営するヌーラボの記事ではOAuthを使用して連携していますので、OAuth認証でも可能と思います
参考: GPTsとBacklog APIの連携について
・ChatGPTの有料プラン契約を済ませておく
【開発手順:GPTsでBacklogの最近の更新を取得し、コメントを翻訳する】
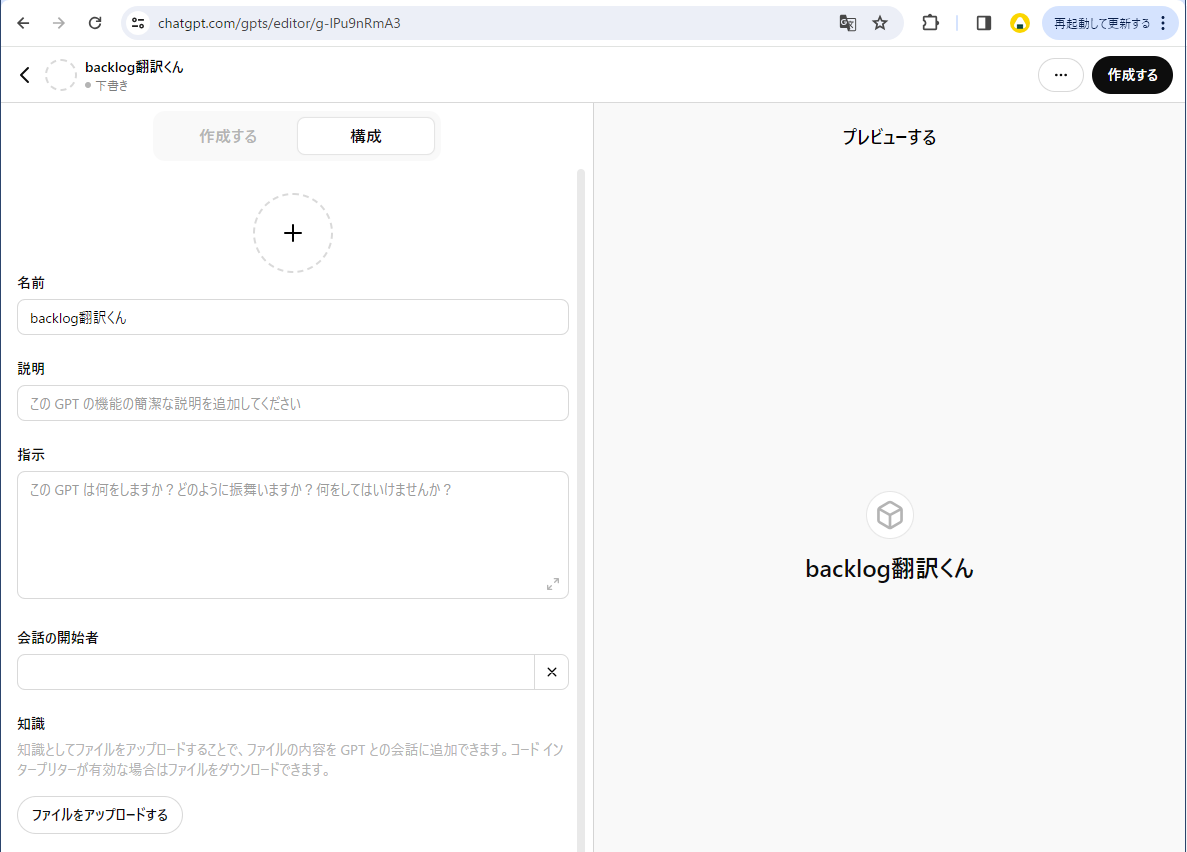
1.GPTsを新規作成する
ChatGPTにログイン後、GPTsの作成画面を開きます。
設定リンク: https://chat.openai.com/gpts/editor
GPTsの作成画面にて、「構成」タブを開きます。
「名前」などの基本情報を入力します。まずは名前だけでも問題ありません。

2.追加設定「GPTで会話データを使用してモデルを改善する」を選択する
「構成」タブのいちばん下に「追加設定」エリアがあり、「∨」を押下すると内容が表示されます。「GPTで会話データを使用してモデルを改善する」設定をONにするかOFFにするか選択できます。
今回はOFFに設定しました。

3.指示の先頭にローカライゼーションについて記載する
「指示」欄に以下の内容を入力しておきます。
応答は日本語で行ってください。日付や時間は日本標準時で処理してください。
これを行っておくと、スムーズに日本語で対話できます。でないと、ちょいちょい「日本語でよろしく」と伝える羽目になります。
日付時刻の処理については、「指示」の中でも細かく設定しないと判定が甘くなることがありますが、それについてはテストして微調整していきましょう。

4.Backlog APIの呼び出し処理を準備する
外部API(今回の場合、Backlog API)をGPTsから呼び出すにあたり、2通りの方法を試しました。
方法1:Custom Actions用のschemaを定義する
GPTsの作成画面にて、「構成」タブ→「新しいアクションを作成する」を実行

「スキーマ」欄に入力します。変更する都度自動保存されます。

入力する内容は、ChatGPTにAPIの仕様解説ページのURLを伝えたり、エンドポイントURLのサンプルを伝えたりするとたたき台を生成してくれます。

APIリクエストのテストは、「テストする」ボタンを押下したり、対話プロンプトで実行を指示したりすることで可能です。
アクセスの許可を求めるメッセージが出た場合は「許可する」または「常に許可する」を押下することで続行可能です。
設定内容に問題があってエラーが発生した場合はChatGPTに修正を頼んだり、自分で微調整したりしながらエラー解消していきます。
参考までに、今回、Backlogの最近の更新の取得API(https://developer.nulab.com/ja/docs/backlog/api/2/get-recent-updates/)を呼び出すために定義したschemaは以下のようになりました。
{
"openapi": "3.1.0",
"info": {
"title": "Backlog API",
"description": "Backlogと連携するためのAPI",
"version": "v1.0.0"
},
"servers": [
{
"url": "https://your_backlog_domain.jp"
}
],
"paths": {
"/api/v2/space/activities": {
"get": {
"operationId": "getRecentActivities",
"summary": "最近の更新の取得",
"description": "Backlogスペースで最近の更新を取得します。",
"parameters": [
{
"name": "apiKey",
"in": "query",
"required": true,
"schema": {
"type": "string",
"default": "**********************************************"
},
"description": "APIキー"
}
],
"responses": {
"200": {
"description": "正常なレスポンス",
"content": {
"application/json": {
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"id": {
"type": "integer"
},
"project": {
"type": "object",
"properties": {
"id": {
"type": "integer"
},
"projectKey": {
"type": "string"
},
"name": {
"type": "string"
}
}
},
"type": {
"type": "integer"
},
"content": {
"type": "object",
"properties": {
"id": {
"type": "integer"
},
"key_id": {
"type": "integer"
},
"summary": {
"type": "string"
},
"description": {
"type": "string"
},
"comment": {
"type": "object",
"properties": {
"id": {
"type": "integer"
},
"content": {
"type": "string",
"description": "コメントの内容"
}
}
},
"changes": {
"type": "array",
"items": {
"type": "object",
"properties": {
"field": {
"type": "string"
},
"new_value": {
"type": "string"
},
"old_value": {
"type": "string"
},
"type": {
"type": "string"
}
}
}
}
}
},
"notifications": {
"type": "array",
"items": {
"type": "object"
}
},
"createdUser": {
"type": "object",
"properties": {
"id": {
"type": "integer"
},
"userId": {
"type": "string"
},
"name": {
"type": "string"
},
"roleType": {
"type": "integer"
},
"lang": {
"type": "string"
}
}
}
}
}
}
}
}
},
"400": {
"description": "無効なリクエスト",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ErrorResponse"
}
}
}
},
"500": {
"description": "サーバーエラー",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ErrorResponse"
}
}
}
}
}
}
}
},
"components": {
"schemas": {
"ErrorResponse": {
"type": "object",
"properties": {
"error": {
"type": "string",
"description": "エラーメッセージ"
},
"code": {
"type": "integer",
"description": "エラーコード"
}
}
}
}
}
}
方法2:「指示」の中に外部APIの呼び出し処理を文章で記載する。
以下のエンドポイントをGETで叩いて。https://your_backlog_domain.jp/api/・・・
簡単なものであればこれだけでも実行が可能でした。
しかし指示の文章中に複数のAPI呼び出しを入れると混乱しやすいようで、処理に番号を振っても別の箇所を実行してしまう事象がみられたので、最終的には「方法1:Custom Actions用のschemaを定義する」を採用しました。
5.「指示」に詳細な処理の流れを記述していく
処理の流れを日本語で記述し、テストして表現の詳細化と微調整を行っていきます。
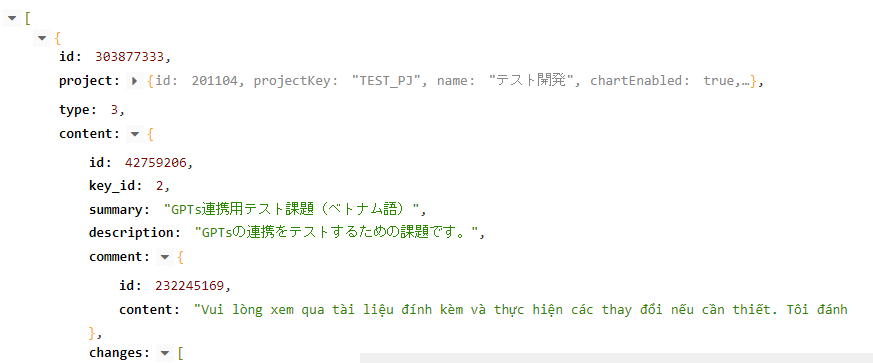
「Backlogスペースの最近の更新の中から外国語のコメントを探させ、翻訳させる」GPTsへの最終的な指示内容は、以下のようになりました。
応答は日本語で行ってください。日付や時間は日本標準時で処理してください。 そのユーザとの最初の会話時、ユーザのapiKeyを確認して、そのユーザとのやりとりではそのapiKeyをずっと使用してください。 再度指示された場合は変更してください。 デフォルトでと言われたら以下を使用。”xxxxxxx” ユーザは、以下を都度指示します。日本標準時です。数字は全角半角が混在します。「9時」は「9:00」、「9時半」は「9:30」と解釈してください。「午前中」は「0:00~12:00」、「午後」は「12:00~24:00」と解釈してください。 ・日付と時間(例:「今日の9時以降」 「2023年9月1日以降」) 処理の流れは以下です。 ---処理開始--- ①getactivitiesを実行。countは固定。 エンドポイントのサンプル:https://your_backlog_domain.jp/api/v2/space/activities?apiKey=ユーザのapiKey&activityTypeId[]=3&count=100 ---①のレスポンスリストでループ開始--- ②レスポンスの"created"を世界標準時から日本標準時に変換したときにユーザの指示に一致しないデータ、レスポンスの"type"が3(コメント)以外のデータは以下の処理はスキップ ③レスポンスの"content"の"comment"の"content"の50%以上が日本語かそれ以外かを判定する ④"content"の"comment"の"content"の50%以上が日本語以外なら日本語に翻訳。"\r\n"と"\n"は改行に置換する。 ⑤issueIdOrKeyを作成。レスポンスの"project"の"projectKey" + "-" + レスポンスの"content"の"key_id" ⑥課題URLを作成。課題URL = "https://your_backlog_domain.jp/" + 作成したissueIdOrKey ⑦課題タイトルを作成。課題タイトル=レスポンスの”content"の"summary" ---ループ終了--- 課題URL、課題タイトル、翻訳結果をセットリストにしてユーザに返答。過去の対話で処理済みのデータも再度教えてください。1件もなければ翻訳の必要性なしと返答してください。「例えば・・・」のような返答は不要です。 ---処理終了---
Backlog APIへのリクエスト実行を安定させるのに時間がかかりましたが、その対応については後述の「エラー対応」にて詳しく説明します。その後は比較的スムーズに(苦労せずにではありませんが、さほど考え込むことなく)処理のテストと指示内容の微調整ができました。
ちなみに、レスポンスデータの中で参照してほしい項目の指示については、「”content”の”comment”の”content”」というような安直な表現でも位置を判断してくれました。
指示内容の微調整を行った主なポイントが4点あります。
- ポイント1:Backlog APIリクエスト用のapiKeyはユーザ毎に設定させるようにした
- ポイント2:日本語かそれ以外かの判定指示は具体的に表現した
- ポイント3:日付・時間の解釈や変換に関する指示は具体的に表現した
- ポイント4:過去の回答を省略させないように指示した
ポイント1:Backlog APIリクエスト用のapiKeyはユーザ毎に設定させるようにした
自分のapiKey固定ですと自分しか利用できないGPTsになります。
対話の中で設定できるように指示しました。
そのユーザとの最初の会話時、ユーザのapiKeyを確認して、そのユーザとのやりとりではそのapiKeyをずっと使用してください。 再度指示された場合は変更してください。
今回apiKey以外は固定の条件としましたが、もっと多くのリクエストパラメータをユーザの指示から取得させると、柔軟な機能にできます。
ポイント2:日本語かそれ以外かの判定指示は具体的に表現した
翻訳指示の文章をこの形に決めるまでに、幾つか試行錯誤がありました。
・レスポンスの"content"の"comment"の"content"の50%以上が日本語かそれ以外かを判定する ・content"の"comment"の"content"の50%以上が日本語以外なら日本語に翻訳。
この部分は、最初はこのような文章でした。
・レスポンスの"content"の"comment"の"content"が外国語かどうかを判定し、外国語であれば次の処理をする ・"content"の"comment"の"content"を日本語に翻訳。
このときのテスト実行では日本語のコメントをすべて抽出して英語に翻訳するという動作になってしまいました。
あらかじめ日本語での応答を指示してはいるのですが、Chat GPTにとっての「外国語」に日本語が含まれてしまったのです。曖昧な表現だったことに気づいたので、次は以下のように修正をしました。
・レスポンスの"content"の"comment"の"content"が日本語かそれ以外かを判定する ・"content"の"comment"の"content"が日本語以外なら日本語に翻訳。
このときのテスト結果は以下です。

一応固有名詞のため伏字としておりますが、赤で示した部分はアルファベット2~3文字の略称でした。アルファベットが混じっている=日本語以外と判定したようです。
それでは誤検出が多すぎるということで、最終的にこちらの表現となりました。
・レスポンスの"content"の"comment"の"content"の50%以上が日本語かそれ以外かを判定する ・content"の"comment"の"content"の50%以上が日本語以外なら、何語であっても日本語に翻訳。
ファイルパスやソースコード等の誤判定されやすい文字列を貼り付けることが多い場合は、さらにそれに合わせた配慮を指示する必要があるかと思います。
ポイント3:日付・時間の解釈や変換に関する指示は具体的に表現した
ユーザの指示する日付・時間は日本標準時、比較対象とする項目”created”は世界標準時です。
日付・時刻まわりは、当初はこのような表現にしていました。
ユーザは、以下を都度指示します。 ・日付と時間(例:「今日の9時以降」 「2023年9月1日以降」) ・レスポンスの"created"がユーザの指示に一致しないデータ、レスポンスの"type"が3(コメント)以外のデータは以下の処理はスキップ
この表現だと日付のみ指定した場合はだいたい機能しますが、「本日の〇時以降」のような線引きがあまり機能せず、例えば「本日の14時以降」と指示しても15時台の対象データを除外してしまったりしました。
見直した結果がこちらです。
ユーザは、以下を都度指示します。日本標準時です。数字は全角半角が混在します。「9時」は「9:00」、「9時半」は「9:30」と解釈してください。「午前中」は「0:00~12:00」、「午後」は「12:00~24:00」と解釈してください。 ・日付と時間(例:「今日の9時以降」 「2023年9月1日以降」) ・レスポンスの"created"を世界標準時から日本標準時に変換したときにユーザの指示に一致しないデータ、レスポンスの"type"が3(コメント)以外のデータは以下の処理はスキップ
これでほぼ意図どおりに判定してくれるようになりました。
ただし「16時以降」と指示した場合に15:59のデータを応答に含んだりしますが、むしろ気遣いとして許容することにしました。
ポイント4:過去の回答を省略させないように指示した
ここまでの微調整でかなり出力結果が安定してきたのですが、繰り返し対話をしていると過去に処理したデータを回答から省略したりするようになり、気遣いなのか処理誤りなのかが判断しづらいことに気が付きました。
そこで、下線のような指示を追加しました。
・課題URL、課題タイトル、翻訳結果をセットリストにしてユーザに返答。過去の対話で処理済みのデータも再度教えてください。1件もなければ翻訳の必要性なしと返答してください。「例えば・・・」のような返答は不要です。
6.最終的な実行サンプル
以下のように出力してくれるようになりました!
出力の見せ方は毎回多少異なっています。たまに途中で指示待ちになってしまったときは「お願いします」と伝えてあげると処理を再開してくれます。

【エラー対応】
上で「Backlog APIへのリクエスト実行を安定させるのに時間がかかった」と書いた件を掘り下げて説明します。
・“MissingKwargsError”:外部APIのリクエストパラメータ命名が特殊な場合に、GPTsがなかなか理解してくれなかった
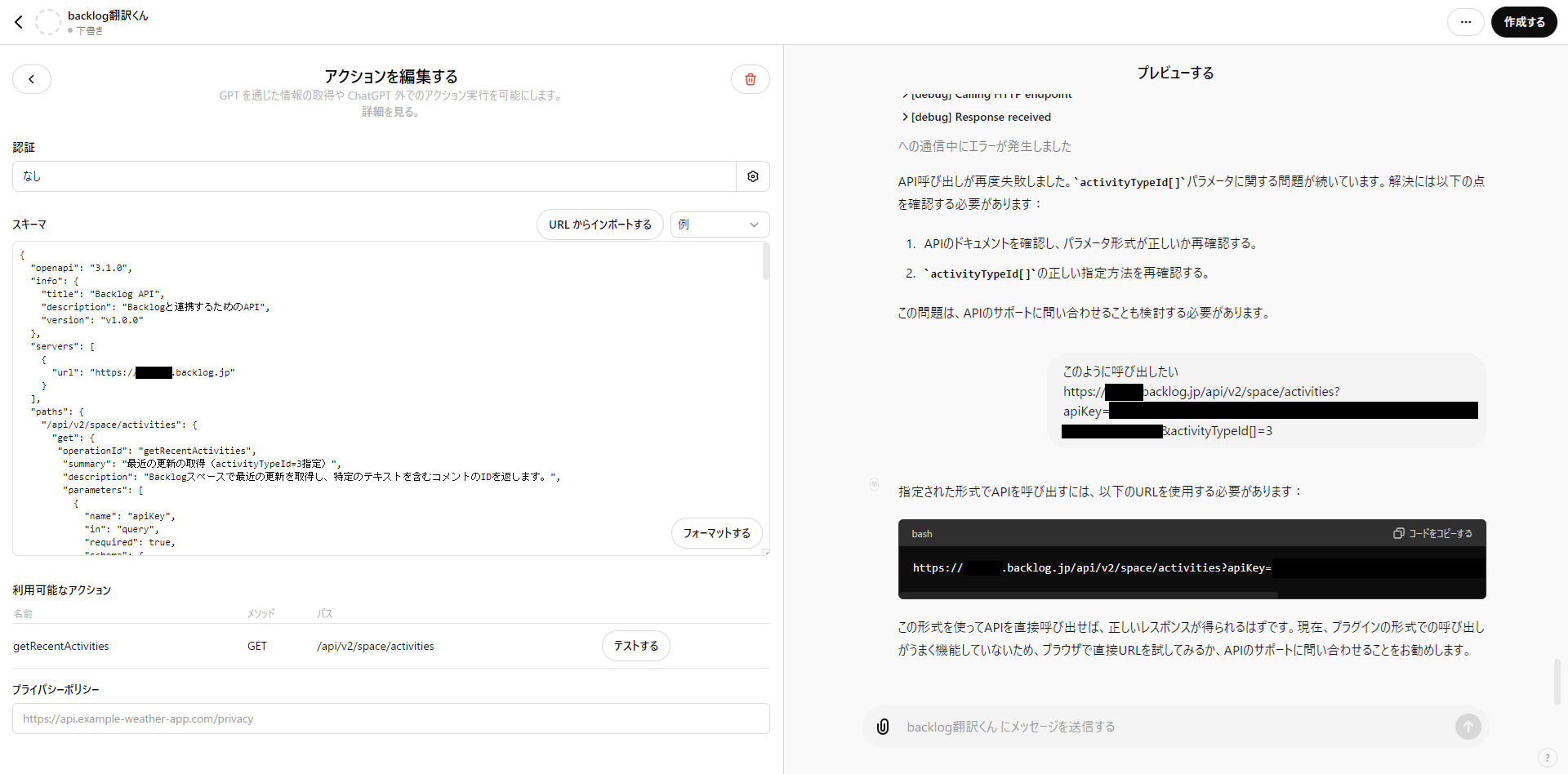
当初、Backlog APIの仕様ページURLをそのままChatGPTに提示してCustom Actions用のschemaを生成させるという手段をとりました。細かい指示をせず、URLだけ伝えても生成してくれます。そのschemaを微調整する程度ですぐにうまくいくことを夢見ていたのですが・・・現実は初心者には厳しく、一番苦労したのがパラメータの設定エラーを意味する“MissingKwargsError”でした。
Backlog APIの仕様ではactivityTypeId\[\]、projectId\[\]、issueTypeId\[\]のように複数指定が可能な項目はパラメータ名に\[\]がついており、単一指定の場合でも\[\]がないとエラーになってしまいます。
例えば、URLパラメータとして指定するなら以下のような感じです。
https://your_backlog_domain.jp/api/v2/space/activities?apiKey=xxx &activityTypeId\[\]=3
しかし、schemaにその通りに定義したり、activityTypeId\[\]そのままでと指示したりしてもGPTsが勝手に\[\]をはずしてリクエストを投げてしまうのです。
何度指示しても、修正して再実行しますと言うけどそこだけは修正してくれない…
“MissingKwargsError”、100回見たかもしれない。
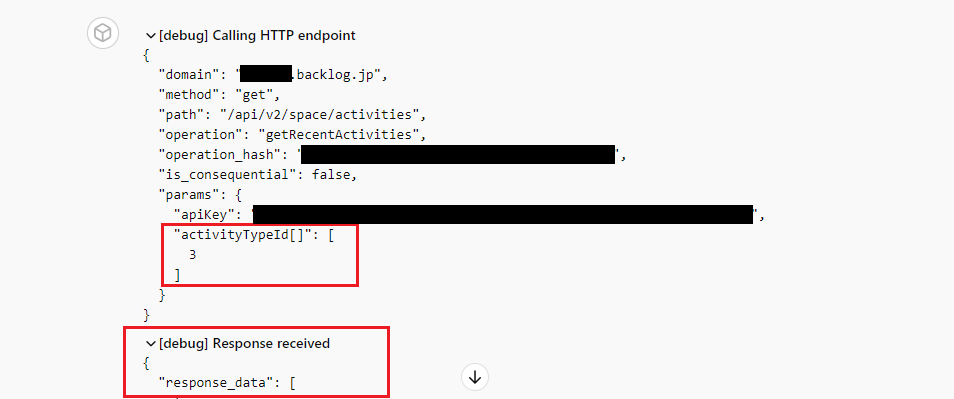
こちらが、APIリクエストテスト中のGPTsとの対話です。
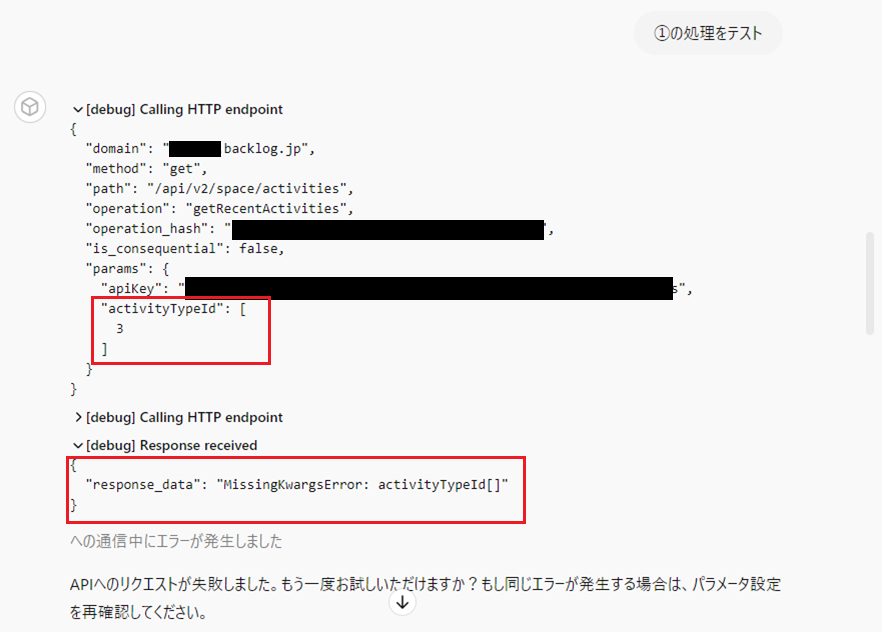
これだけで1時間以上はまってしまったのですが、何度か「解決したかに見えた瞬間」がありました。
エラーとなったときにリクエストとレスポンスの詳細を見ると毎回こんな感じで、activityTypeId\[\]に対する“MissingKwargsError”となっていました。
この直後に「パラメータ名は\[\]そのままで!」と指示することを何回か繰り返していると
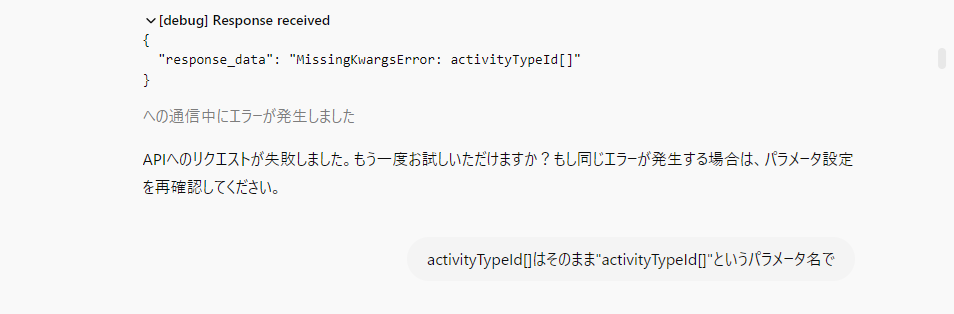
ついにキタ!!(response_dataが返ってきている=意図どおりリクエスト実行できています)GPTsと作成者の心が通じあった(かに見えた)瞬間です。
直前のエラーと作成者の指示の関係をGPTsが理解してくれれば、その場の実行には反映してくれるようです。作成者側が慣れていれば、理解させるための会話の流れがスムーズに作れるようになるのかもしれません。
これで解決したかに見えましたが、翌日になって再実行したら元に戻っており、やはり出力が安定しないことがわかりました。時々はうまくいくのですが、「毎回それでやって」とお願いしてもその次の実行は失敗するというようなことを繰り返してしまいました。最終的には、問題となるactivityTypeId\[\]のパラメータを指定しないでリクエストを実行し、GPTsにレスポンスの中身をチェックさせてactivityTypeId\[\]=3のデータをその後の処理対象とさせる方式に変更することにしました。
通常のコーディングであれば1分で反映して終わることなのに
自分(作成者)は何が悪いか理解しているのにChatGPTになかなか理解させられないもどかしさを感じました。
【次回予定】
今回は「GPTsにBacklogスペースの最近の更新から外国語のコメントを探させ、翻訳させる」処理を開発しました。
次回は、その翻訳結果を課題コメントの追加APIでBacklogに登録させる処理に挑戦したいと思っております。
今回掲載したschema定義やGPTsへの指示内容はコピペOKですので、どなたかの参考になればと思います!
熊本事業所 Y・M

